
If you spend any amount of time online these days, you’ll hear about two things ad nauseum: The meltdown of Twitter and the wonders of AI (artificial intelligence), specifically text generated by tools like ChatGPT or Google’s Bard.
I haven’t had a chance to use ChatGPT because it’s always overloaded with users when I try and I’m not inclined to pay a subscription for a service that I want to test. Google’s Bard has a waitlist.
I have given Character.AI [https://beta.character.ai] a try and wanted to argue with the results it was giving me regarding creating a character from the 1850s in central Minnesota. Let me just say that AI chatbots aren’t particularly good at niche history.
Anyhoo, I’m tracking these developments in AI because they are interesting, but I’m trying not to get sucked into the hype. I follow Emily Bender on Mastodon (@emilymbender@dair-community.social). Bender is a linguist who studies large language models (LLMs), which are the resources that AI tools use to learn from. If you wanted to create a chatbot that answers questions about healthcare, you’d train it on healthcare-related information that’s been digitized. (I’m assuming these LLMs have been trained on digitized information because I don’t think bots have leapt into physical books to read them.)
Bender has been actively warning people not to be fooled into thinking these AI chatbots are somehow sentient. She also regularly discusses the ethics involved in using AI tools and the creation of regulations to keep AI from causing harm. She coined the term “stochastic parrot,” which “is an entity “for haphazardly stitching together sequences of linguistic forms … according to probabilistic information about how they combine, but without any reference to meaning.”” That quote comes from a great article on Bender and her work called You Are Not a Parrot from the New York Intelligencer. [https://nymag.com/intelligencer/article/ai-artificial-intelligence-chatbots-emily-m-bender.html]
No matter how convincing the output from these AI chatbots sounds, there’s no intelligence behind the tools themselves. The true intelligence comes from all the information they have scraped, whether the information is good, bad, or indifferent.
In order to ethically use AI, Bender believes we need transparency about what information is fed into the large language models behind each tool. So far, the big players in the AI chatbot field are being mum about the sources behind their LLMs.
However, The Washington Post recently did some analysis regarding Google’s C4 data set, which is being “used to instruct some high-profile English-language AIs, called large language models, including Google’s T5 and Facebook’s LLaMA.” [Inside the secret list of websites that make AI like ChatGPT sound smart – https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/]
According to the article, 15 million websites form the basis of the C4 data set. These include sites like patents.google.com, Wikipedia, Kickstarter, Patreon, and news sites like The Guardian, New York Times, and WaPo, all the sorts of popular websites you’d expect to see in such a data set. The C4 data set also included propagandist news sites, so it’s immediately apparent that whatever AI uses this data set may end up with less-than-trustworthy results.
A big surprise in the analysis is that the “data set contained more than half a million personal blogs,” including those on Medium, WordPress, LiveJournal, and Tumblr.
Being a blogger, that made me sit up and take notice.
WaPo provided a tool within the article in order to see which websites were part of the data set.
Of course, I had to plug in the URLs of some of my blogs. Surely, my inconsequential musings would not be part of this data set.
My earliest blogs did not turn up in the results, but I was very surprised to find this site, maryewarner.com, as well as several others I’ve worked on, appear. Shockingly, they did not rank at numbers 14,999,995 to 15 million. WaPo used tokens, “small bits of text used to process disorganized information,” to rank the websites.
Here’s how the various blogs I’ve kept ranked.



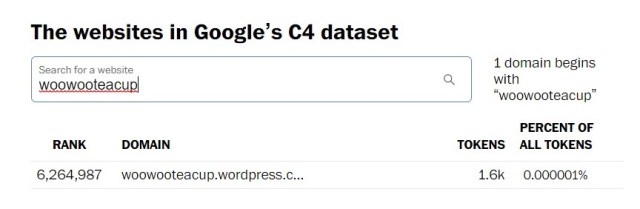
The above four websites are personal, but one website I built and maintained for my previous employer, the Morrison County Historical Society, has had contributions from many, many people since it launched in 2002.
Here’s its ranking in the C4 data set.

While I was astonished to find maryewarner.com ranking around 1 million of the 15 million websites in the C4 data set, I am gobsmacked that morrisoncountyhistory.org ranked at 124,346.
If Character.AI isn’t using the C4 data set, perhaps it should. It’d have a better chance of creating a more accurate historical character from central Minnesota.
So, what does it mean to have websites I’ve created and written for scraped in order to train AI?
On the one hand, it feels good to have my work used to further a technological advance, and to know that my words are living beyond me in some fashion. It’s also a bit of an ego boost, if I’m being honest.
However, many of the companies doing this work are in it for profit and they didn’t get permission to use my work in this way. I’m more than peeved at corporate exploitation and this is more of the same. Companies feel they can take whatever resource they want without compensation and that’s not right. That they are dodging transparency and ethics in the process of training their AI makes me feel as though I’m an unwitting part of their crappy behavior. If they want to use my work, I’d like to put some stipulations on it, like requiring that they reveal it is being used to train their AI and that they follow ethical rules to reduce potential harm.
At the moment, I’m conflicted as to whether having my websites used to train AI is a good thing, particularly in the long term. I’ll have to see how this field develops, but I suspect I’ll be conflicted for some time.
Discover more from Without Obligation
Subscribe to get the latest posts sent to your email.